

Dando continuidade na série de Fundamentos de Banco de Dados, nessa postagem vamos entender melhor o que é um banco de dados relacional.
Antes de iniciar falando sobre o modelo relacional, vou fazer uma “breve introdução” sobre alguns tópicos.
Primeiramente, vamos falar sobre SQL.
SQL (Structured Query Language) foi desenvolvido nos anos 70 pela IBM para atender ao seu produto RDBMS chamado System R.
SQL é uma linguagem padrão ANSI e ISO baseada no modelo relacional, ela foi projetada para consultar e gerenciar dados em um RDBMS. Se tornou um padrão ANSI em 1986 e um padrão ISO em 1987 e desde então tem sido lançados revisões para o padrão da SQL ao longo dos anos.
Diferente de outras linguagens de programação, o SQL requer que você especifique o que deseja obter e não como obter.
A SQL tem muitas categorias, incluindo DDL (Data Definition Language), DML (Data Manipulation Language) e DCL (Data Control Language).
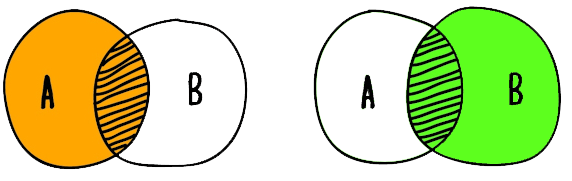
Falando um pouco sobre Teoria dos Conjuntos, ela é um dos ramos da matemática em que o modelo relacional está baseado pois uma relação é como um conjunto de tuplas, algumas operações de joins entre tabelas podem ser facilmente demonstradas a partir da teoria dos conjuntos.
Outro ramo da matemática no qual o modelo relacional está baseado é a lógica do predicado, o predicado é uma propriedade ou expressão que armazena ou não um valor, ele é verdadeiro ou falso.
No modelo relacional eles são usados para manter a integridade lógica dos dados e definir suas estruturas.
Um exemplo de predicado sendo utilizado de forma a impor a integridade é uma constraint definida em uma tabela.
Após explicar um pouco sobre a teoria dos conjuntos e a lógica do predicado podemos entrar no modelo relacional que é o assunto principal dessa postagem.

O modelo relacional é um modelo semântico que é baseado na teoria dos conjuntos e na lógica do predicado para a representação dos dados.
Foi criado por Edgar Frank Codd em 1969 em um relatório de pesquisa da IBM denominado “Derivability, Redundancy, and Consistency of Relations Store in Large Data Banks” e foi feito uma versão revisada em 1970 com a publicação do artigo “A Relational Model of Data for Large Shared Data Banks”.
O objetivo do modelo relacional é representar os dados de uma forma consistente e com o mínimo ou nenhuma redundância através de conjuntos de tabelas inter-relacionadas o que torna os bancos de dados mais flexíveis, tanto na forma de representar as relações entre os dados como na tarefa de modificação de sua estrutura.
Espero que tenham gostado desta postagem!
Aguardem que vem mais conteúdo pela frente!
Até a próxima!
